Si ton site est lent ou sature aux heures de pointe, tu te demandes peut-être si ton hébergement WordPress est bien dimensionné. Entre les php workers WordPress, les paramètres php fpm max children, la configuration opcache WordPress, et l’hébergement WordPress trafic, il y a de quoi se perdre. L’objectif de cet article : t’expliquer simplement le dimensionnement serveur WordPress, comment éviter les files d’attente côté PHP-FPM, quels indicateurs surveiller, et comment mener des tests de charge réalistes pour choisir l’offre adaptée à ton trafic réel. Tu repars avec une méthode concrète, actionnable, et des réglages de base pour stabiliser tes performances.
Pourquoi c’est critique ? Parce que WordPress, surtout avec WooCommerce, un LMS ou un espace membre, exécute régulièrement du code non mis en cache (utilisateurs connectés, panier, paiement, recherche, Ajax…). Quand la demande dépasse la capacité de traitement des workers PHP, une file se forme : la latence explose, puis les erreurs 502/504 apparaissent. La bonne nouvelle : en comprenant comment dimensionner les workers et régler FPM/OPcache, tu peux reprendre le contrôle — sans forcément changer d’hébergeur du jour au lendemain.
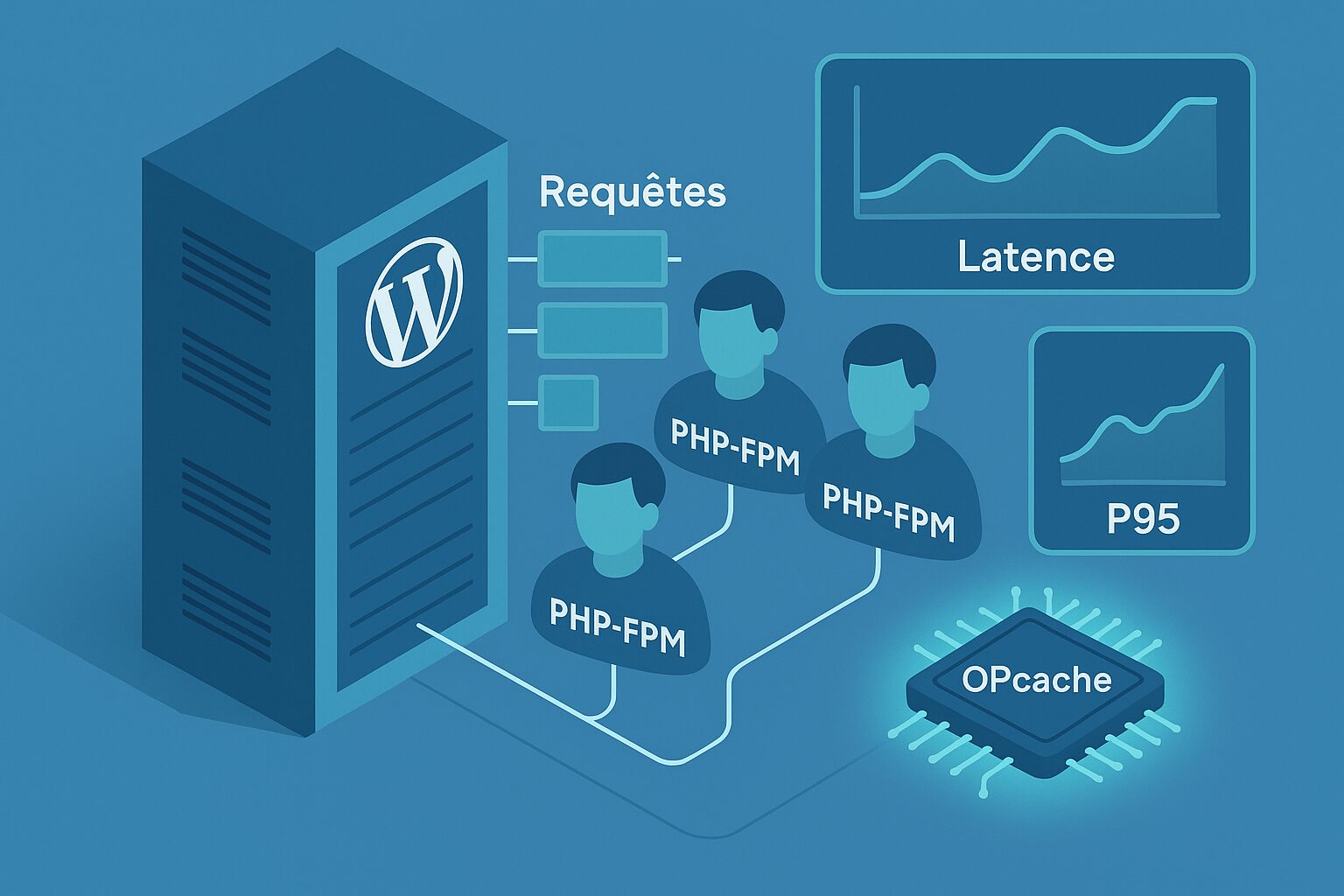
PHP workers WordPress : ce qu’ils font vraiment
Un « PHP worker » (sous PHP-FPM) est un processus capable de traiter une requête PHP à la fois. Concrètement, chaque consultation d’une page non cachée, appel à admin-ajax.php, requête REST API ou exécution d’un hook cron occupe un worker jusqu’à la fin du traitement. Si 10 requêtes arrivent simultanément et que tu n’as que 4 workers disponibles, 4 seront traitées, 6 attendront en file.
Workers ≠ requêtes par seconde
Un malentendu classique : « j’ai 10 workers donc je peux traiter 10 requêtes/seconde ». Faux. Les workers gèrent la concurrence, pas le débit absolu. Le débit dépend aussi du temps de traitement d’une requête. Une règle simple : capacité théorique ≈ (workers / temps de traitement moyen). Si une requête moyenne dure 300 ms (0,3 s) et que tu as 10 workers, la capacité théorique est d’environ 33 RPS (10 / 0,3). Si la latence grimpe à 800 ms, la capacité tombe à 12–13 RPS.
Files d’attente : pourquoi la latence explose
Quand les requêtes entrantes dépassent la capacité des workers, une file d’attente côté FPM se remplit. Les requêtes patientent avant d’être servies, ce qui ajoute une latence « cachée » non visible dans le temps d’exécution PHP pur. Si la file grossit trop, tu vois apparaître des 502/504 et des timeouts en amont (Nginx/Apache). Le pire ? Une latence moyenne qui paraît « correcte » mais un P95 qui s’envole à cause de la queue.

PHP-FPM expliqué simplement (et les bons paramètres)
PHP-FPM est le gestionnaire de processus PHP. Il alloue, recycle et pilote les workers. C’est là que tu règles le « nombre maximum de workers » via pm.max_children (souvent appelé à tort php fpm max children). Trois modes existent : pm = static, pm = dynamic et pm = ondemand.
- static : nombre fixe de workers. Prévisible, utile sur des serveurs dédiés bien dimensionnés.
- dynamic : démarre un nombre initial, ajuste avec des min/max. Bon compromis pour la plupart des hébergeurs managés.
- ondemand : crée les workers à la demande puis les tue quand ils sont inactifs. Économique en RAM mais moins réactif sous charges soudaines.
Les paramètres FPM clés
pm.max_children: nombre max de workers. Détermine la concurrence maximale.pm.start_servers,pm.min_spare_servers,pm.max_spare_servers(mode dynamic) : stabilité et réactivité du pool.pm.process_idle_timeout(mode ondemand) : délai avant de tuer un worker inactif.pm.max_requests: nombre de requêtes traitées par processus avant recyclage. Utile pour limiter les fuites mémoire (plugins/stack imparfaits).request_terminate_timeout: coupe les requêtes trop longues ; évite de monopoliser un worker à l’infini.
Comment choisir pm.max_children ?
Deux contraintes : la RAM et le CPU. Un worker FPM consomme de la mémoire (code, extensions, variables, buffers). Sur WordPress + extensions courantes, compte en moyenne entre 40 et 120 Mo par worker (cela varie selon ton thème, tes plugins et le pic de données PHP). Mesure sur ton environnement en production (ou staging) pour affiner.
- RAM : (RAM disponible pour PHP) / (conso moyenne par worker) ≈ plafond de workers. Garde une marge pour Nginx/Apache, MySQL/MariaDB, Redis, système.
- CPU : viser au départ ~1 à 2 workers par cœur logique si ton code est majoritairement CPU-bound. S’il y a beaucoup d’I/O (APIs, disque, réseau), on peut monter un peu plus.
Exemple : sur un 4 vCPU / 8 Go RAM, si tu réserves 3 Go à MySQL/Redis/Système, il reste ~5 Go pour PHP. Avec 80 Mo/worker observés, pm.max_children ≈ 62 théoriquement (5000 / 80). Mais côté CPU, on évite d’en lancer 60 sur 4 vCPU ! Démarre plutôt à 12–16 workers, mesure, puis ajuste.
Capacité cible : une formule simple
Capacité (RPS) ≈ workers / temps_moyen. Pour atteindre 50 RPS avec 300 ms de temps moyen, il faut ~15–20 workers, si le CPU suit. Ajoute une marge de 20–30 % pour absorber les pics. Retiens aussi que la mise en cache pleine page réduit fortement la charge : une page servie par Nginx ou par un plugin de cache ne consomme pas de worker PHP.
OPcache WordPress : la base pour réduire la charge CPU
OPcache stocke le bytecode PHP compilé en mémoire pour éviter de recompiler les scripts à chaque requête. Sans lui, chaque worker perd du temps CPU, et tu as besoin de plus de workers pour atteindre le même débit. C’est un pilier du dimensionnement serveur WordPress.

Réglages OPcache recommandés (base)
opcache.enable=1,opcache.enable_cli=0(sauf besoins spécifiques en CLI)opcache.memory_consumption=192à512Mo sur des sites moyens à grosopcache.interned_strings_buffer=16à64opcache.max_accelerated_files=20000à100000selon le nombre de fichiers PHPopcache.validate_timestamps=1en prod, avecopcache.revalidate_freq=60(ou via déploiement contrôlé)opcache.jit: sur PHP 8.x, le JIT apporte peu à WordPress ; garde-le désactivé ou en mode conservateur.
Surveille le hit rate (viser >99 %), la mémoire libre OPcache et le nombre de scripts mis en cache. Une saturation d’OPcache augmente la latence et l’usage CPU. Pour les détails de configuration et le sens exact de chaque directive, consulte la documentation officielle OPcache.
Du front au back : où se perdent les millisecondes
Accélérer WordPress sous charge ne se limite pas aux workers. Le parcours d’une requête implique :
- Le réseau et le CDN : un CDN réduit la charge sur PHP en servant assets et pages mises en cache aux visiteurs éloignés.
- Nginx/Apache : gère les connexions, TLS, compression, cache HTTP ; un micro-cache Nginx peut servir les pages aux non-connectés pendant 1–5 secondes.
- PHP-FPM : exécute le code PHP (theme, plugins, WordPress core).
- Base de données : requêtes MySQL/MariaDB ; indexation et requêtes lentes influencent la durée d’occupation d’un worker.
- Object cache (Redis/Memcached) : évite des requêtes SQL répétitives, diminue la pression sur FPM.
Cas critiques : WooCommerce, membres, éditeurs
- WooCommerce : sessions, panier, paiements, webhooks ; beaucoup de trafic non caché et
admin-ajax.php. - Sites membres / e-learning : utilisateurs connectés, autorisations spécifiques ; la mise en cache pleine page est souvent limitée.
- Sites média : fort trafic anonyme, mais pics viraux ; le cache HTTP/CDN change la donne.
Tests de charge réalistes : comment faire (et quoi mesurer)
Pas de dimensionnement sans test. Un test de charge crédible reproduit le mix de pages et de comportements de tes utilisateurs : ratio pages cachées vs non cachées, sessions connectées, Ajax, recherche, panier.
Outils et méthodologie
- k6 (scriptable, moderne). Voir la doc tests de charge k6.
- Alternatives : Locust, JMeter, Artillery. Pour un premier cadrage, un burst court peut suffire, puis enchaîne avec un test palier (step) et un test d’endurance (30–60 min).
Étapes :
- Définis le scénario : 70 % pages publiques (cachables), 20 % fiches produits/article avec filtrage, 10 % paniers/checkout (non cachés). Adapte selon ton site.
- Paramètre les utilisateurs virtuels (VU) et le ramp-up : ex. de 0 à 200 VU en 10 minutes, maintien 10 minutes, puis pic à 300 VU sur 3 minutes.
- Mesure en corrélation : RPS, latence P50/P95/P99, erreurs, longueur de file FPM, CPU/RAM, I/O disque, connexions DB, requêtes lentes.
- Teste en connecté et non connecté : le cache ment si tu ne simules que des visiteurs anonymes.
- Nettoie le bruit : désactive les CRON horaires pendant le test, fige l’indexation de recherche, évite les sauvegardes automatiques.

Comment lire les résultats
- Latence P95 sous 600–800 ms pour les pages dynamiques lourdes, sous 200–300 ms pour les pages cachées.
- Taux d’erreur < 1 % ; si tu vois des 502/504, regarde la file FPM et les logs Nginx.
- CPU : si tu es à 100 % longtemps sur tous les cœurs, tu manques de CPU (ou ton code est trop lourd).
- RAM : si l’OOM killer frappe ou que le swap grimppe, baisse
pm.max_childrenou ajoute de la RAM. - FPM : file qui s’allonge = workers saturés ; augmente
pm.max_children(si RAM/CPU OK) ou améliore le cache/SQL.
Réglages FPM concrets pour démarrer
Ces valeurs sont des points de départ, à ajuster par la mesure :
- Mode :
pm=dynamic pm.max_children: 8–12 (petit site), 16–32 (site moyen), 32–64 (gros site). Vérifie la RAM.pm.start_servers: 25–40 % depm.max_childrenpm.min_spare_servers: 25–30 %pm.max_spare_servers: 50–60 %pm.max_requests: 500–2000 (selon stabilité des plugins). Surveille le RSS des processus.request_terminate_timeout: 60–120s (checkout/API lente). Ajuste si nécessaire.
Active les slow logs FPM (ex. 0.5–1s) pour identifier les scripts lents. Côté base, regarde les slow_query_log MySQL/MariaDB pour éliminer les requêtes trop coûteuses (index, JOIN, meta queries non sélectives).
OPcache : vérifier que ça fonctionne
Une fois activé et dimensionné, installe un petit tableau de bord OPcache (il en existe des open-source) ou expose les métriques via ton APM. À surveiller :
- Mémoire utilisée vs libre. Garde 5–10 % de marge libre en régime établi.
- max_accelerated_files : ne sature pas ; augmente si le nombre de scripts s’en approche.
- Hit rate : vise > 99 %. Sinon, trop d’invalidations (plugins qui chassent les caches, déploiements non atomiques, timestamps mal réglés).
Cache de page, objet et CDN : soulager les workers
Chaque couche de cache retire de la pression des workers PHP :
- Cache pleine page (Nginx micro-cache, WP Rocket, LiteSpeed Cache) : idéal pour le trafic non connecté.
- Object cache (Redis/Memcached) : mémorise les résultats de requêtes et d’APIs ; diminue le temps d’occupation d’un worker.
- CDN : sert les assets et parfois les pages HTML ; réduit la latence géographique.

Dimensionnement selon le type de site et le trafic
Blog / site vitrine avec cache agressif
- Trafic anonyme majoritaire.
- Workers modestes suffisent : 4–8 workers sur petite VM si le cache est bien réglé.
- OPcache généreux (128–256 Mo) pour rester en taux de hit élevé.
WooCommerce (panier, paiement, clients connectés)
- Très peu de cache en tunnel d’achat ; attention à
admin-ajax.phpet aux webhooks. - Démarre à 16–32 workers selon CPU/RAM. Active Redis object cache, optimise les requêtes produit/stock.
- Surveille le P95 paniers/checkout, pas seulement la page d’accueil.
Sites membres, LMS, intranet
- Beaucoup d’utilisateurs connectés, pages personnalisées.
- Privilégie la stabilité des workers (pm=dynamic), Redis, et un OPcache large.
- Teste des scénarios connectés en priorité.
Trafic international et pics viraux
- CDN obligatoire pour aplanir les pics et rapprocher le contenu de l’utilisateur.
- Micro-cache côté front + règles de purge propres.
- Monte les workers si la part non cachée augmente, sinon investis d’abord dans le cache/CDN.
Bonnes pratiques de monitoring sous charge
Ce que nous suivons chez WP Builders lors d’un audit :
- FPM : process actifs/inactifs, longueur de file, temps moyen de traitement, recycle, slow logs.
- OPcache : mémoire, fichiers accélérés, hit rate.
- Base de données : requêtes/s, latence, locks, slow log, index manquants.
- Nginx/Apache : connexions actives, 4xx/5xx, compression, cache HIT/MISS.
- Système : CPU par cœur, charge moyenne, I/O, swap.

Erreurs courantes qui tuent les performances
- Confondre workers et RPS : tu augmentes
pm.max_childrensans fin, mais le CPU/DB ne suit pas. - OPcache sous-dimensionné : taux de hit bas, compilations répétées.
- Object cache absent sur un e-commerce : trop de requêtes SQL redondantes.
- Thème/Plugins lourds : boucles non indexées, queries meta, images non optimisées.
- Tests de charge non représentatifs : uniquement des pages cachées ; tu crois que tout va bien… jusqu’au Black Friday.
Plan d’action en 7 étapes
- Activer et dimensionner OPcache (192–512 Mo, hit rate >99 %).
- Installer un object cache (Redis) et corriger les requêtes lentes.
- Mesurer la conso RAM par worker et fixer un
pm.max_childrenréaliste. - Régler FPM :
pm=dynamic,pm.max_requests500–2000, slow logs. - Mettre un cache pleine page et, si possible, un micro-cache Nginx/CDN.
- Écrire un scénario de test (connecté + anonyme) et exécuter k6/Locust.
- Itérer : éliminer les goulots, recalibrer, re-tester jusqu’à un P95 stable.
Besoin d’un dimensionnement WordPress béton ?
Audit, tuning FPM/OPcache et tests de charge : notre équipe optimise votre hébergement pour encaisser le trafic sans stress.
Choisir une offre d’hébergement selon le trafic réel
Pas de recette unique, mais des repères :
- Mutualisé d’entrée de gamme : 2–4 workers partagés, OK pour vitrines à faible trafic caché. Limité pour les besoins dynamiques.
- Hébergement managé WordPress : isolation, FPM réglable, Redis/CDN intégrés. 8–32 workers selon plans. Bon ratio coût/perf.
- VPS/Serveur dédié : liberté totale. Demande compétences pour FPM, Nginx, MySQL, sécurité, sauvegardes.
- Cluster/Autoscaling : pour pics massifs et haute dispo. Complexité et coût supérieurs.
Pour décider, base-toi sur tes mesures : RPS cible, P95 visé, part de pages non cachées, conso RAM/CPU durant les pics. Choisis l’offre qui encaisse ton pic avec 20–30 % de marge. Mieux vaut une VM un peu plus large et bien réglée qu’un mutualisé “illimité” saturé.
Exemples de dimensionnement (ordre de grandeur)
Vitrine locale avec 50k visites/mois
- Cache agressif + CDN.
- VM 2 vCPU / 4 Go, OPcache 128–192 Mo, 6–8 workers.
- P95 public visé : < 200 ms (cache HIT), P95 non caché : 400–600 ms.
WooCommerce 150–300 ventes/jour, pics pub
- VM 4–8 vCPU / 8–16 Go, Redis, OPcache 256–512 Mo.
- 16–32 workers, micro-cache pour pages catalogue non connectées.
- P95 checkout : 600–800 ms sous 100–150 VU, taux d’erreur < 0,5 %.
Éditeur média 1M vues/mois, pics viraux
- CDN + micro-cache 2–5 s, purge sélective.
- VM 4 vCPU / 8 Go, 12–16 workers suffisent (trafic massivement caché).
- Optimise Nginx et base (requêtes d’archives, widgets, recherche).
Sécurité, maintenance et pérennité
Des réglages performants ne servent à rien sans un socle fiable : mises à jour contrôlées, sauvegardes, surveillance 24/7, correctifs de sécurité, et tests après déploiement. Un WordPress sain tient mieux la charge parce qu’il évite les fuites mémoire, les tâches CRON incontrôlées et les extensions vulnérables qui consomment des ressources.
Comment WP Builders peut t’aider
Notre équipe accompagne quotidiennement des sites WordPress vitrine, e-commerce et médias. Nous auditons ta stack (Nginx/Apache, PHP-FPM, OPcache, MySQL, Redis), mesurons la conso réelle des workers, écrivons des scénarios de charge, puis ajustons pm.max_children, pm.max_requests, OPcache et le cache applicatif. Résultat : une latence P95 maîtrisée, moins d’erreurs sous pic, et un hébergement calibré sur ton trafic, pas sur une fiche commerciale.
Conclusion
Comprendre les PHP workers, régler PHP-FPM (notamment pm.max_children) et dimensionner OPcache te donnent des leviers concrets pour stabiliser WordPress sous charge. Ajoute un cache efficace, un object cache, un CDN quand c’est pertinent, et surtout des tests de charge réalistes. Tu pourras alors choisir, en toute confiance, l’offre d’hébergement adaptée à ton trafic réel — avec une marge de sécurité pour les pics. Besoin d’un coup de main pour cadrer, tester et optimiser ? On est là pour t’épauler, rapidement et sans jargon.


